Siguiendo con el tema de Virtual Patching ahora toca ver cómo funciona y los beneficios que puede aportarnos.
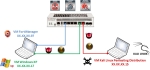
Para ello he creado un entorno con dos PCs interconectados por medio de un Fortinet Fortigate Rugged 60D configurándolo con motores Antivirus, IDS/IPS y Control de Aplicación. La parte de firewall la he dejado con un “permit any any any” (IP origen, destino y puerto, respectivamente) Hay que recordar que cada una de ellos lo podemos configurar en dos modos, “Monitor” o “Block”. Con el primero, en caso de que se detecte algún patrón que puda quedar recogido dentro de las reglas y firmas, no se tomará ninguna acción, sólo se registrará el evento y se dejará pasar. En cambio con “Block”, valga la redundancia se bloqueará y la amenaza será paralizada.
Luego, estas características han de aplicarse, o no, a las reglas de Firewall en él configuradas.
En cada uno de estos PCs he virtualizado un total de 3 máquinas.
Una con Kali Linux desde la cual simularemos la actividad de un atacante. Lanzaremos un escaneo de puertos con Nmap, escáner de vulnerabilidades con Nessus, intento de intrusión con Metaesploit y Armitage y por último copiar en un recurso de red el fichero EICAR.
Otra con un Windows XP vulnerable, el objetivo. Se ha elegido este ya que posee vulnerabilidades que para un ejemplo pueden ser fácilmente explotables. Aparte porque su uso en entornos industriales y o vida prolongada es aún bastante común.
Por último un Fortinet FotiManager con funciones FortiAnalyzer desde donde gestionaremos el equipo Fortigate Rugged 60D. Lo he querido utilizar ya que con un despliegue de varios equipos resulta aconsejable no sólo por la gestión centralizada sino porque nos permite almacenar los logs, analizar tráfico, sacar informes, ver registros, etc.
Todo queda resumido de la siguiente manera:
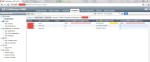
En la imagen siguiente se muestra cómo el equipo Fortigate bloquea un total de 9965 amenazas catalogadas en un total de 1993 incidentes, provenientes de la IP XX.XX.XX.15 de la máquina Kali Linux. Esto es debido a que la aplicación Nmap envía sucesivamente paquetes para que en función de las respuestas obtenidas se pueda determinar si un equipo está activo, o no, puertos abiertos; versiones de aplicaciones, servicios; etc.
Para conocer un poco más recomiendo la siguiente lectura, pincha aquí.
En esta otra se puede ver que el equipo destino tiene la IP XX.XX.XX.17.
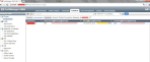
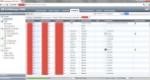
En la siguiente imagen se muestra las “sondas” enviadas desde el equipo Kali Linux identificando alguna aplicación que otra:
Como se puede apreciar éstas han sido bloqueadas no pudiéndose obtener datos sobre el equipo objetivo, el XP. Esto mitigaría la etapa inicial de recolección de información que un atacante llevaría a cabo y poder, a partir de ahí, realizar otro tipo de acciones sobre nuestros sistemas.
Obviamente habría que configurar las reglas del firewall del modo más restrictivo posible y sobre el tráfico que dejamos pasar aplicar el análisis de los motores Antivirus, IPS y Control de Aplicación. Sin embargo para este ejemplo se ha querido dejar así para ver el comportamiento de la aplicación Nmap y qué es lo que sucede si no empleamos un cortafuego. Pero como como digo, siempre, siempre, siempre, ha de restringirse el tráfico sólo al estrictamente permitido por medio de estos firewalls.
Esto es todo por hoy, pero os debo las siguientes entradas sobre escáner de Vulnerabilidades, Metaesploit y EICAR Test File.
No s vemos en la próxima, y como siempre digo, se agradece cualquier comentario al respecto.
Como comentaba en la entrada anterior, hace poco terminé el curso sobre Ciberseguridad en Sistemas de Control y Automatización Industrial impartido por el Instituto Nacional de Ciberseguriad (INCIBE) antes, INTECO.
Dentro de su contenido, en uno de sus módulos se trataba el tema de los incidentes de seguridad sobre dichos sistemas, analizando desde los posibles objetivos potenciales hasta las deficiencias técnicas, pasando por controles de acceso físico pobres o incluso nulos.
Entre esos puntos se apuntaba como orígenes a la red corporativa y a cortafuegos perimetrales mal configurados. En el primero de ellos, se explicaba que tanto los sistemas empresariales como industriales comparten la misma infraestructura de comunicaciones permitiendo llevar ataques desde la red corporativa a la de control aprovechando alguna vulnerabilidad en aquéllos. En lo referente a los cortafuegos perimetrales, se comentaban las malas configuraciones sobre ciertos protocolos y también, no considerar el sentido de las conexiones. Como ejemplo se hablaba de una intrusión en los sistemas de control, la ejecución de un “payload” en ellos e iniciar una conexión a un equipo remoto empleando un puerto abierto en el firewall.
Partiendo de la base que ninguna red es igual ya que las necesidades y usos pueden ser bien distintos, en la entrada de hoy voy a hablar de dos aspectos que afectan a las ideas descritas en los apartados anteriores.
Por mi experiencia, es muy común que equipos corporativos convivan con los de control dentro del mismo switch. Por ejemplo, en una cadena de producción tenemos un PC donde ejecutamos distintas aplicaciones relacionadas con el proceso de fabricación, mientras que en otros puertos tenemos los autómatas que controlan la maquinaria (robots, sensores, válvulas, etc.). También puede ocurrir que existan incluso puntos de acceso inalábricos para aquellos dispositivos no cableados tipo PDAs industriales, lectores de códigos de barras, PCs portátiles de personal de mantenimiento, etc. ¡Y posiblemente todo dentro de la misma VLAN! Resultaría costosísimo, o incluso inviable, implementar dos o tres infraestructuras paralelas para separar físicamente todo el tráfico, así que la realidad es que unos y otros deben “viajar” por el mismo equipo y por la misma red, aunque separados lógicamente mediante el uso deVLANs.
Por otro lado, debemos pensar que a la hora de interconectarlo todo, no se puede implementar cortafuegos por cada enlace, subred, equipo, etc. para regular el tráfico a permitir o denegar. Si bien la inversión, condiciona en gran medida la solución tecnológica a utilizar (salvo que sobre el dinero, que viendo los tiempos que corren es poco probable…), debemos pensar, en lo a la parte técnica se refiere, que los switches nos pueden ofrecer una serie de ventajas que, a veces, los cortafuegos no lo hacen. Por ejemplo, mayor densidad de puertos y uso de módulos SFP para distintos medios físicos como cable y fibra óptica. También es cierto que los cortafuegos realizan tareas que no hacen los switches. Unos no son mejores que los otros, sino que cada cual hace su papel y se complementan.
A estas ideas debemos sumar también la implantación de medidas que garanticen una alta disponibilidad de los servicios prestados, con lo que aparte de equipos de comunicaciones, de seguridad, control, automatización, etc. debemos disponerlo todo de tal manera que en caso de producirse un fallo, la red pueda seguir funcionando sin que esto suponga un impacto en la calidad del servicio ofrecido.
Como bien dice el refrán “Una imagen vale más que mil palabras” he creado un escenario para tratar de entender mejor lo dicho. He utilizado la aplicación de Cisco Systems, Packettracer, utilizada para la preparación de las certificaciones CCNA y CCNP, entre otras.
Basándome en los criterios de este post, aquí os dejo la topología:
Para explicarlo empezaremos de izquierda a derecha.
Tenemos el equipo “Switch Acceso” (Switch L2) al que se conectan por un lado los autómatas PLC-01 y PLC-02, y por otro un PC que pueda ser utilizado para la ejecución de aplicaciones relacionadas con la actividad industrial. También se ha incluido una impresora, como un elemento de red más que pueda ser utilizado para la impresión de algunos documentos, órdenes de montaje, códigos de barras para temas logísticos, etc.
Para segmentar el tráfico, los PLCs, el PC y la impresora se han situado en VLANs distintas. PLC-01 y PLC-02 en la VLAN 10 con direccionamiento 192.168.10.0 /24; y PC-01 y Printer0 en la VLAN 20, y red 192.168.20.0/24. Como puerta de enlace será la primera IP de ambas redes, la .1.
Dado que es un entorno de alta disponibilidad, se ha configurado en los switches “sw-core-01” y “sw-core-02” (Ambos multicapa o L3) interfaces virtuales para cada una de las VLANs, y en ellas, el protocolo HSRP, aunque también hubiera servido VRRP. Si no sabéis o queréis refrescar los conceptos de interfaces virtuales o dejo un link a un artículo que publiqué hace un tiempo, aquí.
Luego tenemos los cortafuegos, que filtrarán el tráfico entre la red de servidores donde se sitúa el servidor de SCADA, Historiadores, etc y el resto. Esta red tiene un direccionamiento 192.168.254.0/24, y está en la VLAN 254. También está configurado HSRP.
No he dibujado la red corporativa como oficinas ya que no viene por ahí el problema de seguridad que quiero explicar, pero de existir, deberían colgar de cada uno de los nodos del firewall, como lo están las dibujadas.
Como podréis ver los cortafuegos tiene un enlace entre sí. Todo tiene una explicación.
Al igual que en los equipos de red tenemos HSRP, VRRP y GLBP para implementar alta disponibilidad, los cortafuegos tienen los suyos también. Lo que se hace es una topología tipo “Activo-Pasivo” o “Activo-Activo”. La primera de ellas, sería equiparable al comportamiento de HSRP y VRRP, donde uno de los nodos soporta todo el tráfico, el “Master”, mientras que el otro está de respaldo, el “Backup”. En caso de que el “Master” falle, el “Backup” entra en funcionamiento. El modo “Activo-Activo” es aquél en el que ambos nodos funcionan a la par, proporcionando no sólo una alta disponibilidad, ya que si uno falla el otro asume su rol, sino que además existe un balanceo de carga ya que se puede repartir el tráfico entre ambos.
En cualquiera de los dos casos, ambos nodos deben tener un enlace donde compartir una tabla con las conexiones que tiene abiertas, ya que si el nodo “Master” falla, el de “Backup” debe seguir permitiéndolas. Si no existiese este enlace y el nodo de “Backup” no tuviese dicha tabla, cuando uno de los equipos finales volviesen a generar tráfico de una sesión ya establecida, las cortarían.
Por no estar hablando siempre de Cisco, Juniper tiene su protocolo NSRP. Os dejo algunos enlaces pero si buscáis en por ahí encontraréis un montón de información al respecto.
Vale, tenemos el PC y la impresora en una VLAN; y los PLCs en otra de tal manera que a nivel de capa 2 los tenemos “aislados” y cada uno en su propio dominio de broadcast. Mismo criterio con los servidores. Sin embargo, los equipos PLC no están todo lo protegidos que debieran.
¿Por qué? Porque si nos fijamos el PC-01 a pesar de estar en una VLAN distinta de los PLCs puede llegar a ellos sin problemas. Vamos a abrir un navegador del PC-01 y la IP del PLC-01.
¿Por qué? Sencillo. Cuando abrimos el navegador el tráfico llega al switch sw-core-01. Como éste tiene acceso a la VLAN donde está la dirección IP de destino, la 192.168.10.100, es el propio switch el que lo envía por la interfaz de la VLAN 10 ya que están ambas en el mismo equipo. La 10 y la 20. Podríamos cambiar manualmente el enrutamiento para que fuese todo al tráfico hacia el firewall y éste lo descartase, pero tampoco tiene mucho sentido hacerlo “subir” hasta ahí para luego descartarlo y ocupar un ancho de banda por poco que sea, nos puede resultar necesario, especialmente a los PLC en su comunicación con el servidor SCADA.
Por tanto, hay una cosa que es clara y es que tenemos que filtrar el tráfico para evitar que ningún equipo de la red 192.168.20.0/24 pueda llegar a la 192.168.10.0/24. Sin embargo, sí que tenemos que permitir el tráfico desde la red 192.168.20.0/24 a cualquier otro equipo de la red.
Así que, ¿qué alternativa tenemos? La alternativa son las ACL, Access List. Pero esto lo dejamos para la siguiente entrada.
Un saludo a todos, nos vemos en la siguiente y no te olvides que puedes seguirnos también en @enredandoconred .