Como hemos comentado en otras ocasiones la separación y segmentación de los entornos IT y OT es la primera medida técnica que debemos tomar. Es necesario definir los perímetros y qué comunicaciones deben permitirse entre uno y otro lado. Para conseguirlo, empleamos Cortafuegos aunque con características adicionales que han dado lugar a los conocidos NGFW. Sin embargo, también podemos contar con otras adicionales, en este caso, para evitar denegaciones de servicio, DoS.
La primera acción que debemos hacer es identificar el tráfico. Definir qué comunicaciones existen en nuestro entorno de control y automatización. Luego, permitirlas en función del criterio que más se ajuste ya sea por IPs, interfaces, servicios, subredes, aplicaciones, protocolos o cualquier otro. Sin embargo, una vez hecho esto y teniendo que claro “qué si y qué no”, también es importante identificar posibles anomalías dentro del mismo pudiendo afectar al funcionamiento del, o los equipos, destino.
Una de las acciones con las que podríamos afectar a las comunicaciones de este ámbito es introduciendo tráfico adicional. Sea este Broadcast, Multicast o Unicast los efectos podrán ser unos u otros ya que dependerá si la electrónica de red lo replica por todos los puertos o sólo por aquél que está dirigido al destinatario.
Si nos referimos a los equipos de control, sabemos que éstos tienen un ciclo de vida mayor con lo que es muy común encontrarnos con equipos antiguos con una capacidad para gestionar comunicaciones mucho más limitada que los equipos actuales. Ante un exceso de tráfico, aunque esté dirigido a un puerto de destino permitido, éstos podrían dejar de responder perdiendo así visibilidad y control.
Hay que tener presente que una denegación de servicio puede no venir exclusivamente de medidas claramente intencionadas. También puede hacerse por un error o mala parametrización de sistemas. Un caso lo podríamos encontrar en los escáneres de vulnerabilidades. Si no los configuramos correctamente y no los ejecutamos acorde a los equipos finales podríamos llegar a comprobar vulnerabilidades de sistemas operativos Windows, Linux, etc. sobre autómatas o controladores que, lógicamente, no los empleen o podrían no hacerlo. Aparte de que los resultados no tendrían sentido, podría desembocar en posibles bloqueos en módulos de comunicaciones, tiempos de respuesta tardíos, entre otros.
Para emular una situación de esta índole he elaborado una Prueba de Concepto empleando el simulador Snap7 y equipos virtuales. No obstante, la prueba fue realizada sobre dos autómatas Siemens S7-400 y S7-300 y los resultados fueron la pérdida de visibilidad desde el servidor que los gestionaba. Los equipos no eran capaces de manipular tanto tráfico. Por supuesto, en un entorno de laboratorio.
La misma sigue el siguiente esquema:

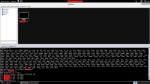
Desde un equipo con una distribución Kali Linux realizamos una inundación de tráfico por medio de la herramienta hping3, efectuando peticiones TCP SYN contra el puerto TCP 102, que es el empleado por el fabricante Siemens. Dicho equipo tendrá una IP 192.168.100.20, mientras que el PLC virtualizado 192.168.20.10.
root@kali:~# hping3 –flood -p 102 -S 192.168.20.10
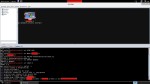
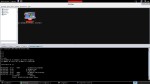
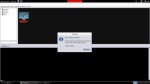
Antes de realizar dicha operación podremos comprobar que el consumo de CPU como de memoria es bajo dada la ausencia de sesiones.

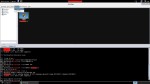
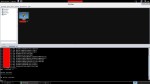
Sin embargo, una vez comenzado el envío de paquetes el consumo de recursos va en aumento:

Si en ese momento decidiésemos conectarnos a dicho PLC simulando un servidor, HMI, etc. veríamos que no sería posible y cómo la propia herramienta muestra un mensaje en la parte inferior de la captura “ISO: An error occurred during…”

En este sentido fabricantes como Fortinet introducen una funcionalidad denominada “IPv4 DoS Policy” que nos va a permitir atajar que, algo o alguien, de una manera intencionada, o no, pueda generar un exceso de tráfico que desemboque en una pérdida de visibilidad o control sobre equipos finales.
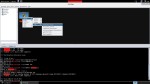
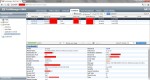
En la imagen siguiente podemos ver los distintos parámetros que podemos definir y parametrizar según sea nuestra necesidad.

Deberemos indicar la interfaz de entrada por dónde esperaremos el tráfico en cuestión, ya sea física o lógica; direcciones IP de origen y destino y servicios. A continuación, hemos de identificar las características a nivel de capa 3 y/o 4 que queremos habilitar y los respectivos umbrales de cada uno de ellos. Este es un trabajo que hemos realizar con cautela ya que nos obliga a tener una estimación acerca de los valores tolerables y qué se escapa de un normal comportamiento. No tenemos porqué habilitar todas las opciones, sino aquellas que consideremos que nos pueden ser de utilidad o tengan sentido dependiendo de la ubicación y exposición del cortafuegos. Finalmente, una de las opciones que sí resulta conveniente habilitar es la opción de registro ya que nos va a permitir disponer de información al respecto, como se puede ver en la imagen siguiente.

Cuando hablamos de cortafuegos, generalmente nos viene a la mente la opción de permitir o denegar tráfico y sobre él aplicarle controles adicionales como Antivirus, IDS/IPS, entre otros. Es cierto, ese su principal cometido. Sin embargo, podemos encontrar funcionalidades que, sin penalizar el rendimiento, pueda ayudar a identificar anomalías de aquél que estamos dejando pasar.
La primera tarea es decidir qué debemos autorizar y qué no. Esto nos va obligar a conocer qué comunicaciones establecen nuestros equipos de control y sistemas asociados. A menudo partiremos de un desconocimiento total ya que nos enfrentaremos a entornos conmutados o enrutados donde no se ha documentado dicha información y obviamente no existen elementos de seguridad perimetral. Si queremos filtrarlas deberemos identificarlas, y entender el por qué deben producirse, o no. No todo lo que veamos debe ser permitido. Probablemente ni tan siquiera los propios usuarios de las instalaciones lo sepan. Es una labor que puede complicarse según sean los escenarios, pero que en cualquier caso, ha de realizarse.
Un buen recurso pueden ser los “Puerto Espejo” o dispositivos como el Siemens TAP 104, que nos ayudarán a replicar tráfico de red y que pueda ser colectado y analizado a posteriori.
Hasta aquí la entrada de hoy.
¡Un saludo nos vemos en la próxima!